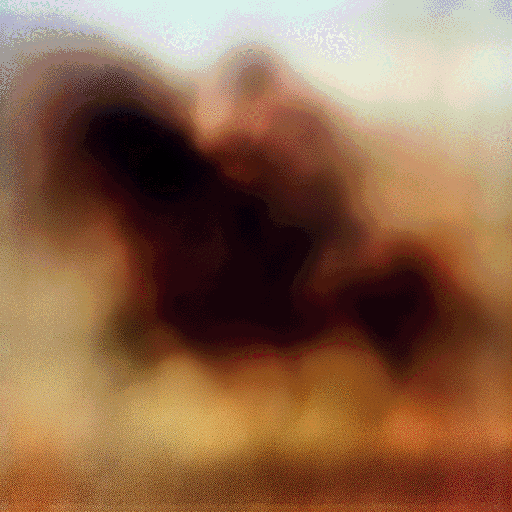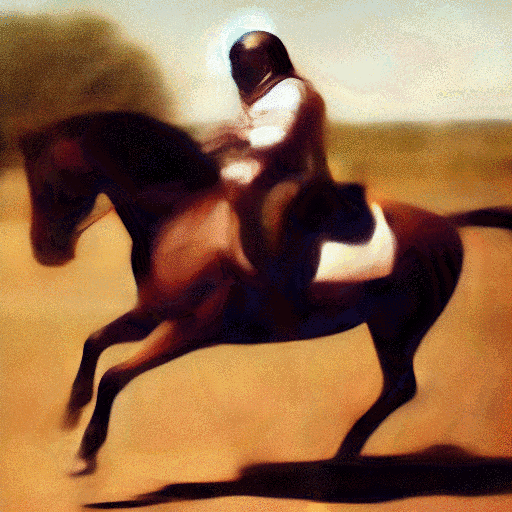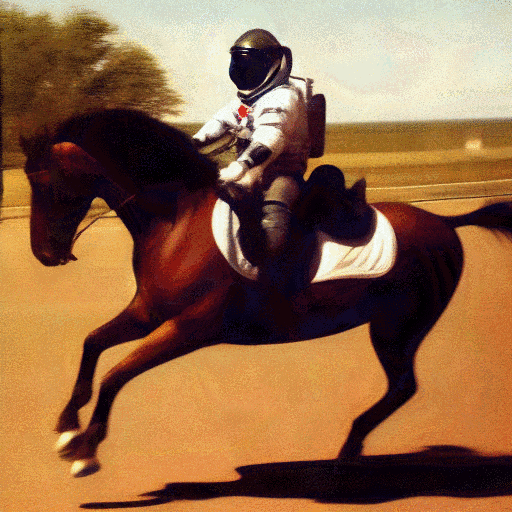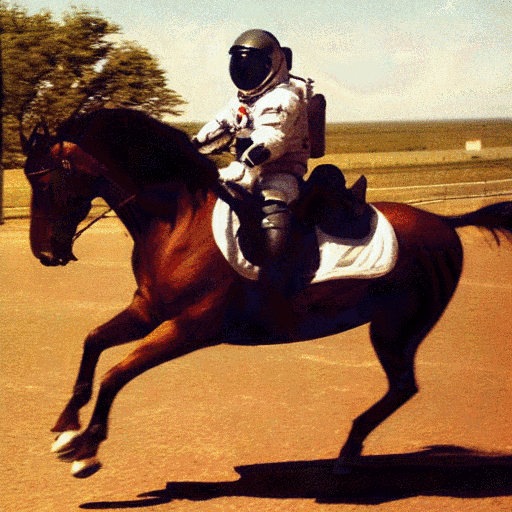 By now, most readers will be aware of recent innovations in the area of image generation with artificial intelligence (AI).
By now, most readers will be aware of recent innovations in the area of image generation with artificial intelligence (AI).
With tools like Stable Diffusion, you can generate original images by supplying text prompts, like “photograph of an astronaut riding a horse”, as shown in the upper right image.
Stable Diffusion does this by starting with random noise, and comparing the random image to an index of images that match the prompt text. The application chooses the image that has qualities closest to the images in its index that match or are close to the prompt text, and then it repeats this process. With each iteration, the image’s qualities get closer and closer to images with the desired tags or text prompt.
This artificial intelligence – so the program is not intentionally drawing a picture of an astronaut on a horse – it’s generating an image with qualities that are similar to the qualities of images that it’s indexed for ‘astronaut’ and ‘horse’.
This is an important difference, and helps explain why these AI images can be amazing, but are very likely to have some weirdness to them.
Did you notice that the horse only has three legs?
Riffusion is a new project that builds on the success of recent AI image generation work, but applies it to sound.
 The way Riffusion works is by first building an indexed collection of spectrograms, each tagged with keywords that represent the style of music captured in the spectrogram.
The way Riffusion works is by first building an indexed collection of spectrograms, each tagged with keywords that represent the style of music captured in the spectrogram.
Once it is trained on this body of spectrograms, the model can use the same approach as Stable Diffusion, interating on noise to get to a sonogram image that has similar qualities to sonograms that match your text prompts.
If you ask for ‘swing jazz trumpet’, it will generate a sonogram that is similar to sonograms that closely match your prompt. The application then converts the sonogram to audio, so you can listen to the result.
The results are currently crude, but demonstrate that the process does result in original audio that matches the text prompts. But the process is limited by a small index of spectrograms, compared to the 2.3 billion images used to train Stable Diffusion. And it’s limited by the resolution of the spectrograms, which give the resulting audio a lofi quality.
It’s unlikely that this process will result in AI generating anything conventionally musical in the near future, because the process does not account for form, the idea that music is sound, intentionally organized in time to create an artistic effect.
The approach shows potential, though. It’s currently up to the task of generating disturbing sample fodder – similar to the way AI image generation, even 6 months ago, was limited to generating lofi creepy images. This suggests that – with a much larger index, and higher resolution spectrograms – it’s likely that AI audio generation could make similar leaps in quality in the next year.
What do you think? Is there a future in music for AI directly synthesizing audio? Share your thoughts in the comments!
via John Lehmkuhl

Been using John’s Unify since day one. Awesome software.
As for AI generated images(which I have been using and having fun with) and now possibly AI music, from what I understand it’s all really just stuff generated from massive databases of info based on key word searches i.e. text input or in this case sonograms.
If you look at the entire internet as just a vast data base where keyword info/searches are used all the time, but now such info can be “rendered” or turned into images or sounds or whatever from universal reference materials and word combinations, sonograms, etc., it seems like a logical extension of such powerful capabilities.
I remember the days when drum machines were supposedly going to be the death of real drummers. I grew up using encyclopedias for info on world stuff, and the local library lol.
Now I can check the weather in Zaboniawherethefuckever, buy stuff and it’s delivered the same day, talk to my doctor, gamble, watch pretty much anything anything, post goofy stuff on forums, become “an influencer” etc. etc. etc etc, all just using a little hand held device that transmits and receives everything thru the air lol. Sorcery!
Technology constantly changes everything.
Itself included.
Oddly, I find this very intriguing. One might say that it is the first intelligent idea to come out in a long time!
I agree. The results are primitive at this point, but they are also intriguing. You can tell that interesting things will come from this.
The results would be much better if they could use spectrograms of logical stems of the music, like bass, lead, drums, etc.
Native Instruments introduced a standard a few years for DJing, Stems, that did just that. If these two ideas could be married together, it could leap things forward.
I agree with the article too about the image resolution. It sounds like this translated directly into a sort of bitcrushed, overcompressed sound. Leverage Apple Silicon GPUs, and crank the spectrogram resolution up. Sound quality would get way better.
fuck yah
I sent a 3-minute Riffusion song through Melodyne to clean it up, added upward compression, a smile eq & limiter to give it some punch, and it came alive. The Garblefarkle language is the best!
Very interesting article. Michael, how have you downloaded the generated music to tweak it like that?
You cant download- it goes on forever. I recorded it for a while and selected 3 minutes.
Interesting, but you can tell it has so far only been trained with a small variety of sounds and musical genres. I wonder how it would sound if I could train it myself with the music I enjoy.
How embarrassing ..freaky AI music sounding better than us. We’re doomed! At least we can spend our unemployed days making more pictures of astronauts on three legged horses. Can’t wait.
winamp …..It really whips the llama’s ass!
McDonald’s is a place to rock.
you get what you ask it for
that may works for pictures
but for sound?
you can’t ask it to create something completely new, its just remixes of trained patterns …
its a dead end.
Astronaut riding a horse is straight out of a Primus video. Does anyone know what kind of music Vincent van Gogh listened to? I don’t know. Do you? AI mimics what it is given with no understanding, only vague instructions. Machines will not create art until machines want art.
“AI mimics what it is given with no understanding, only vague instructions”. Kind of just how humans do it, if you think about it. Although “mimics” might not be the best chosen word (for either humans or machines), the way humans “learn” over 95% of their behaviors (both covert behaviors and overt behaviors) is, essentially, through trial and error. The thing that humans excel at, though, is in their capacity for deluding themselves to see processes within themselves that most likely don’t exist. Take the process of “free will. Most humans believe they have it but it really is only an illusion. Machines will learn, just as humans do, as soon as the engineers understand the paradigm by which humans learn. Unfortunately, going about it the way they currently are is really setting cybernetics back quite a long way.